.gif)


Redis 数据分片
一、Hash取模分片
我们先从简单、经典的hash取模算法说起。
假设Redis集群现在有3个节点,使用经典的hash取模算法进行数据分片,实际就是一个节点一个数据分片,分为了3片,这是一种非常简单的分片方式。
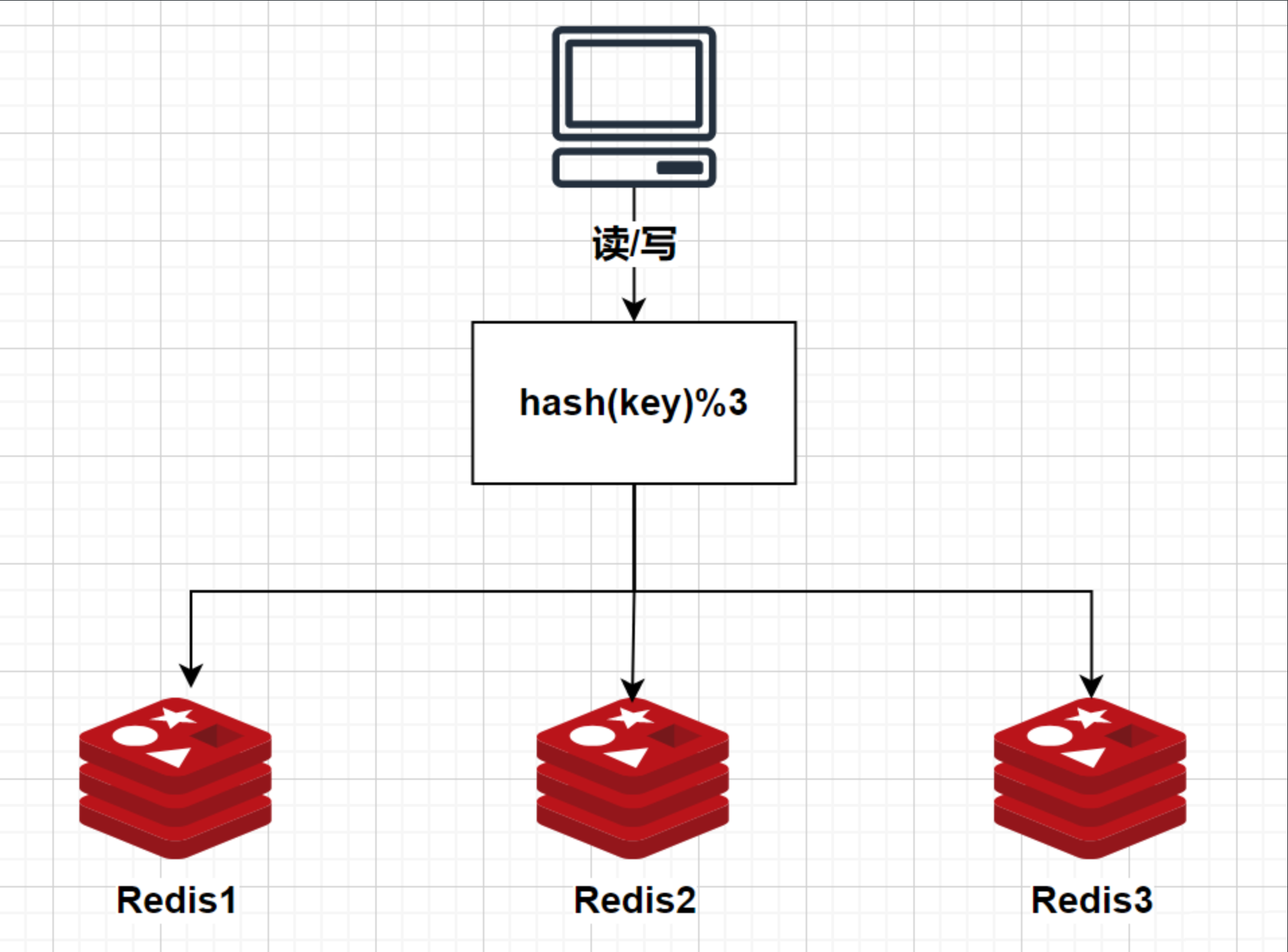
但这种算法存在一个很严重的问题,就是对扩/缩容很不友好,假设现在再加一个节点,变成4个节点:
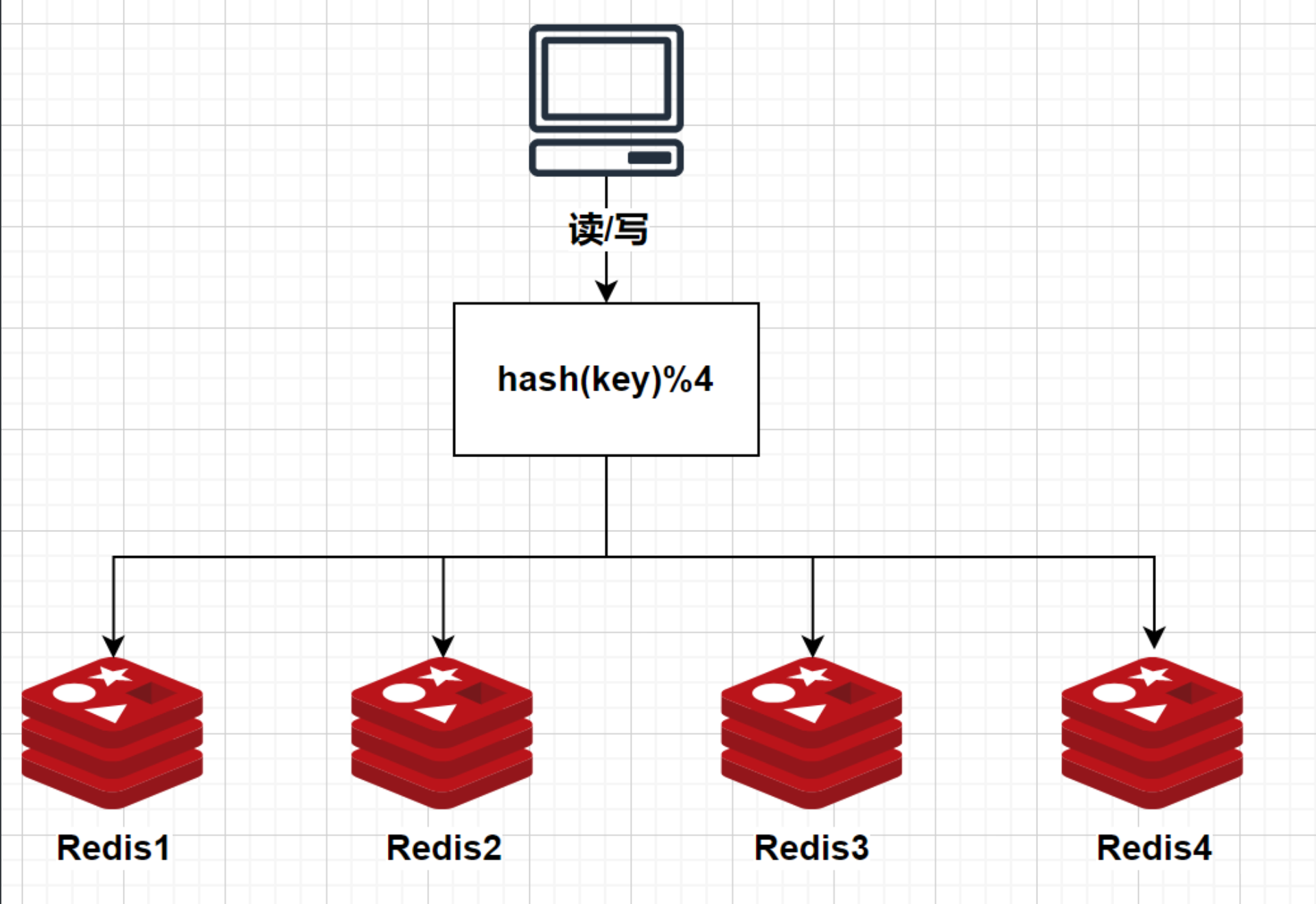
我们可以看到,原来的分片路由算法是:hash(key)%3,现在的分片路由算法是:hash(key)%4
分片路由的变更就意味着大量的key需要进行数据迁移,按上述例子来说,使用hash取模算法的话,要有75%的数据需要进行迁移。
那该怎么解决呢,有两个方案:一个方案是,如果非要用这种算法,建议采用多倍扩容的方式,这样就只需要迁移50%的数据。另一个方案则是采用一致性hash分片的算法。
总结一下:
优点:
简单粗暴,直接有效。
缺点:
数据节点伸缩时,会导致大量数据迁移(最少50%数据要迁移,一般有80%)。
二、一致性Hash算法分片
2.1 什么是一致性Hash算法
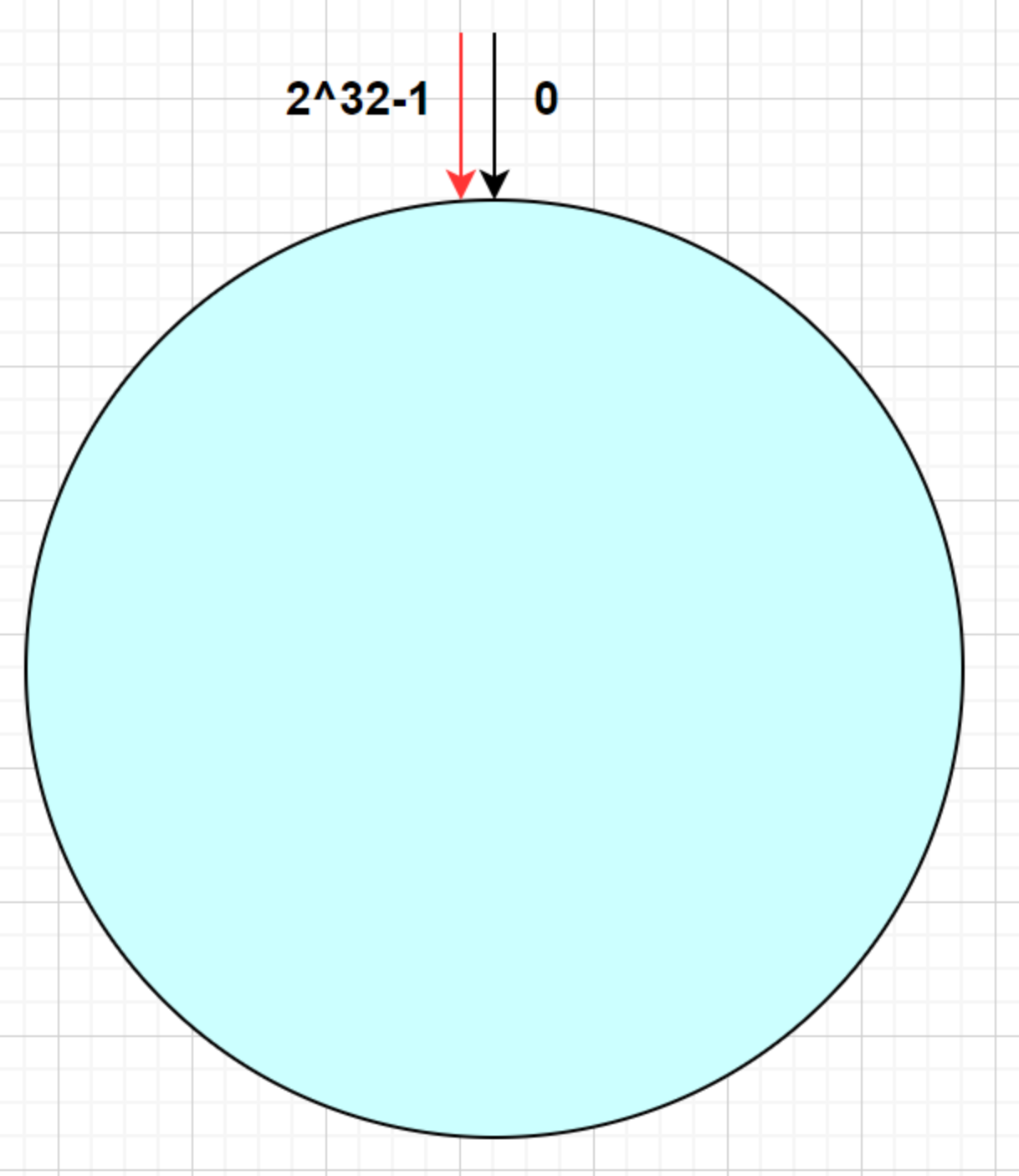
一致性Hash算法在1997年由麻省理工学院提出,引入了一个0~43亿的整数哈希环(0~2^32),把节点的ip和端口及其它信息作为字符串的对象进行散列计算,目的是为了解决分布式缓存数据变动和映射问题,简单地说就是当服务器个数发生变化的时候,尽量减少影响客户端到服务端的映射关系。
2.2 key分配过程
key值是如何经过一致性hash算法计算后分配到对应的redis节点的呢?这里就需要采用一种特殊得结构:Hash槽位环,一致性哈希算法把2^32个slot槽位虚拟成一个圆环,该环首尾相连(0=2^32),如下图:
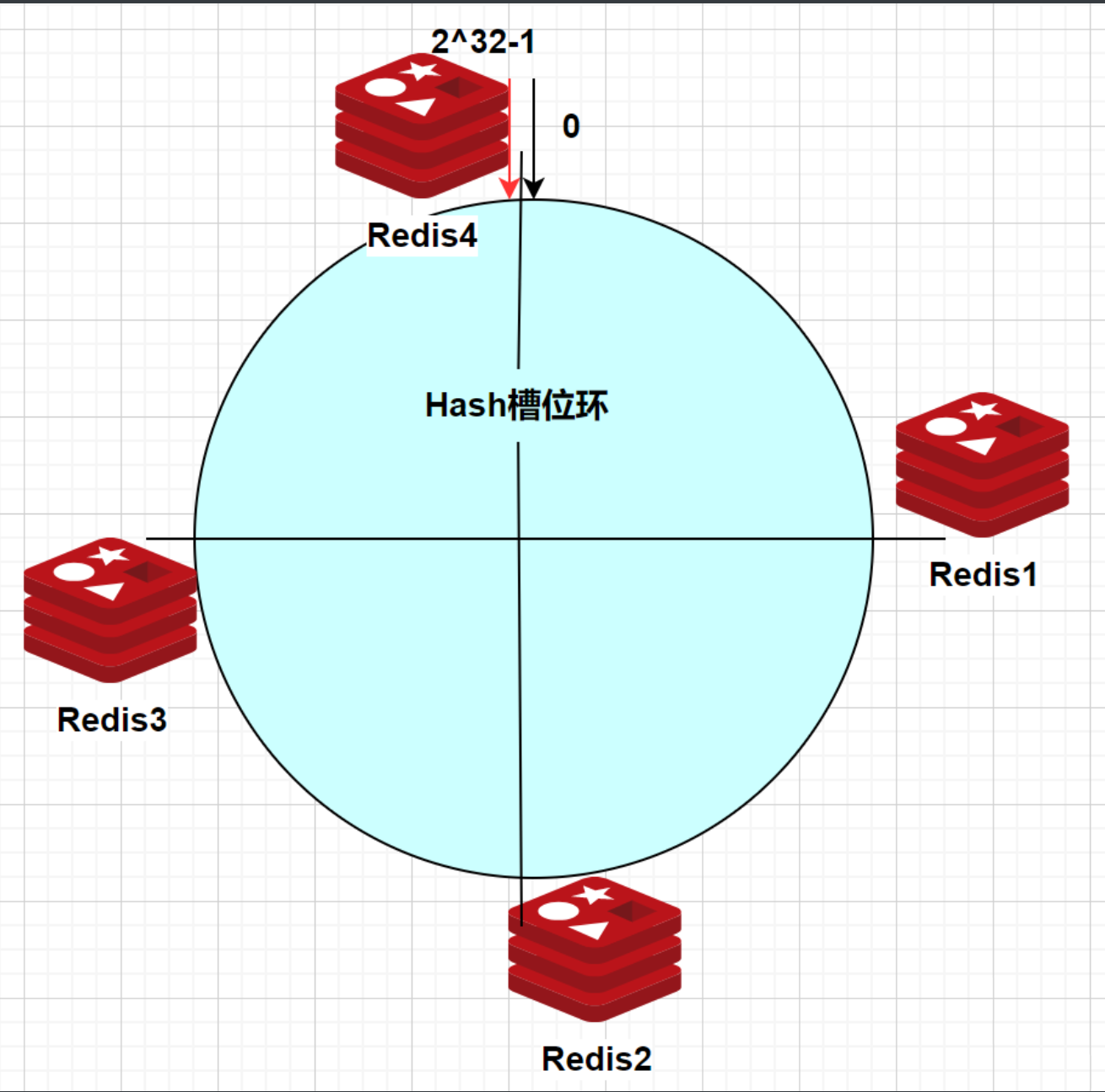
假设现在有4个redis节点,那么这4个节点如何确定自己在环上的位置的呢?
将各个服务器进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希(hash(ip)),这样每台机器就能确定其在哈希环上的位置。
假设经过计算后这4个节点的位置如下,每个节点负责存储一个slot分段:
那么key是如何分配的各个节点的呢?key分配过程核心有两个阶段:
第一阶段:进行slot槽位计算,每个key进行hash运算,被hash后的结果与2^32取模,获得slot槽位。
第二阶段:在hash槽位环上,按顺时针去找到最近的redis节点,那么这个key将会被保存在这个节点上。
2.3 三个经典场景
2.3.1 Key入环
key入环即key上述key分配过程,不再赘述。
2.3.2 新增redis节点
假设现在需要对redis节点进行扩容,经过hash(ip)后,redis5落在了redis1和redis2之间,如下图:
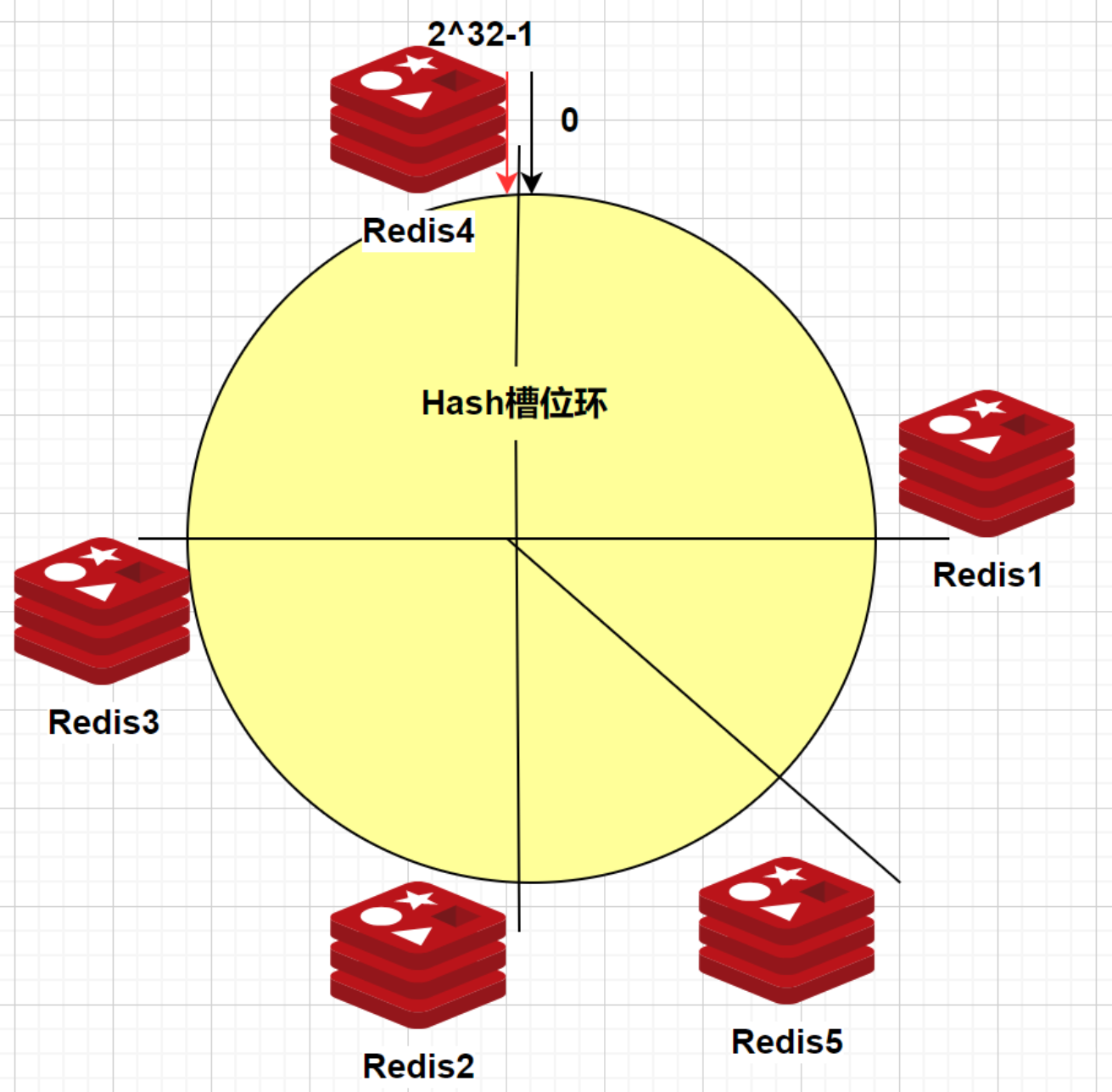
添加了redis5之后,会对所有redis2上的数据,进行重新检查:
如果redis2上的数据,顺时针方向最近的新节点不是redis2而是redis5的话(也就是hash计算后落在了redis1和redis5之间的key),那么这些数据将会被迁移至redis5上。
而其它节点redis1、redis3和redis4上的数据不会受影响。
2.3.3 删除redis节点
假设把redis2节点剔除了,会发生什么?如下图:
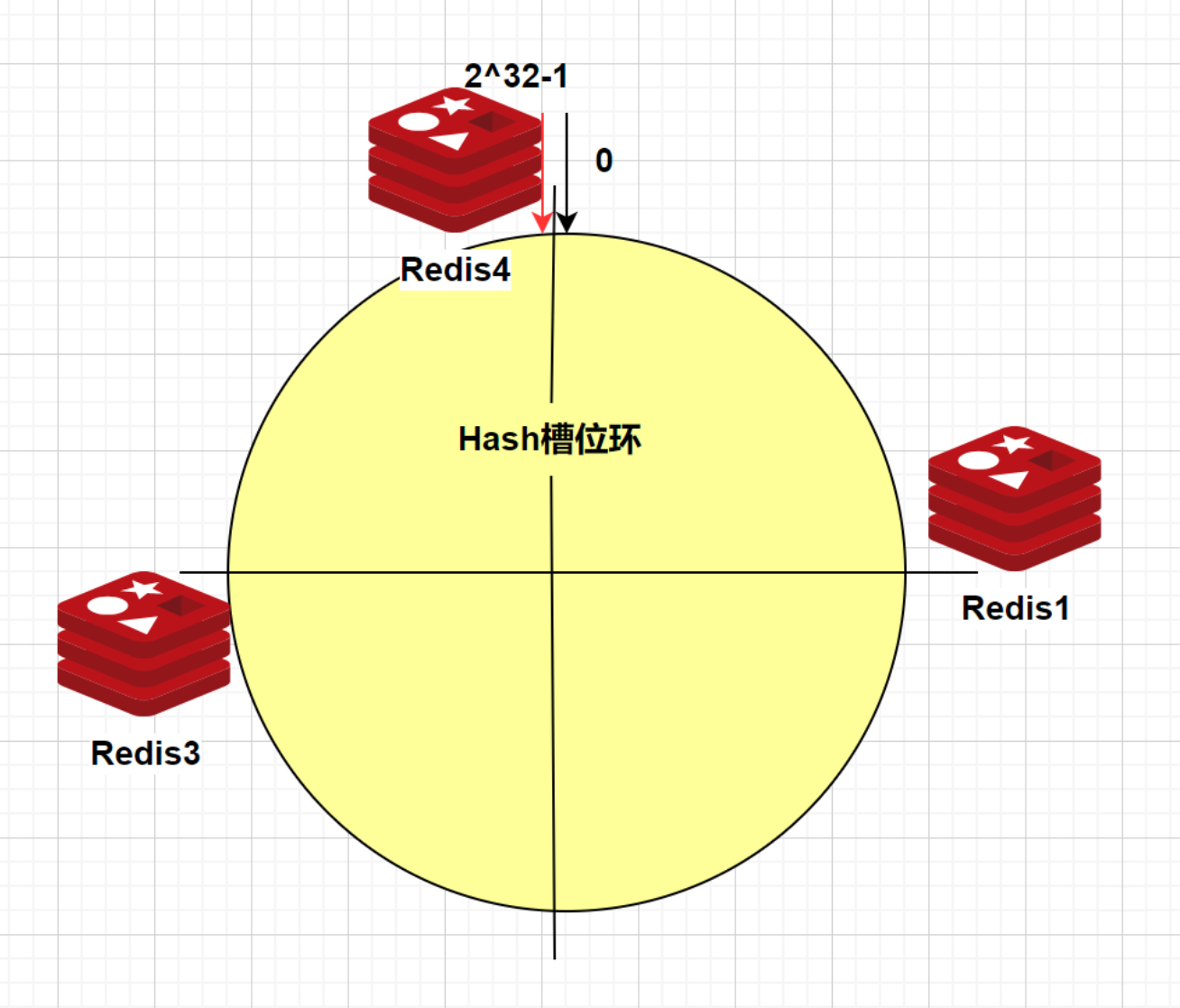
那么redis2节点上的数据将会被迁移到redis3上(顺时针最近),redis1和redis4不受影响,这也是一致性哈希算法存在的最大问题:数据倾斜问题。
那么如何解决这个问题呢?虚拟节点。
2.4 虚拟节点
虚拟节点可以理解为逻辑节点,不是物理节点。假设在hash环上,引入了32个虚拟redis节点,如下图:
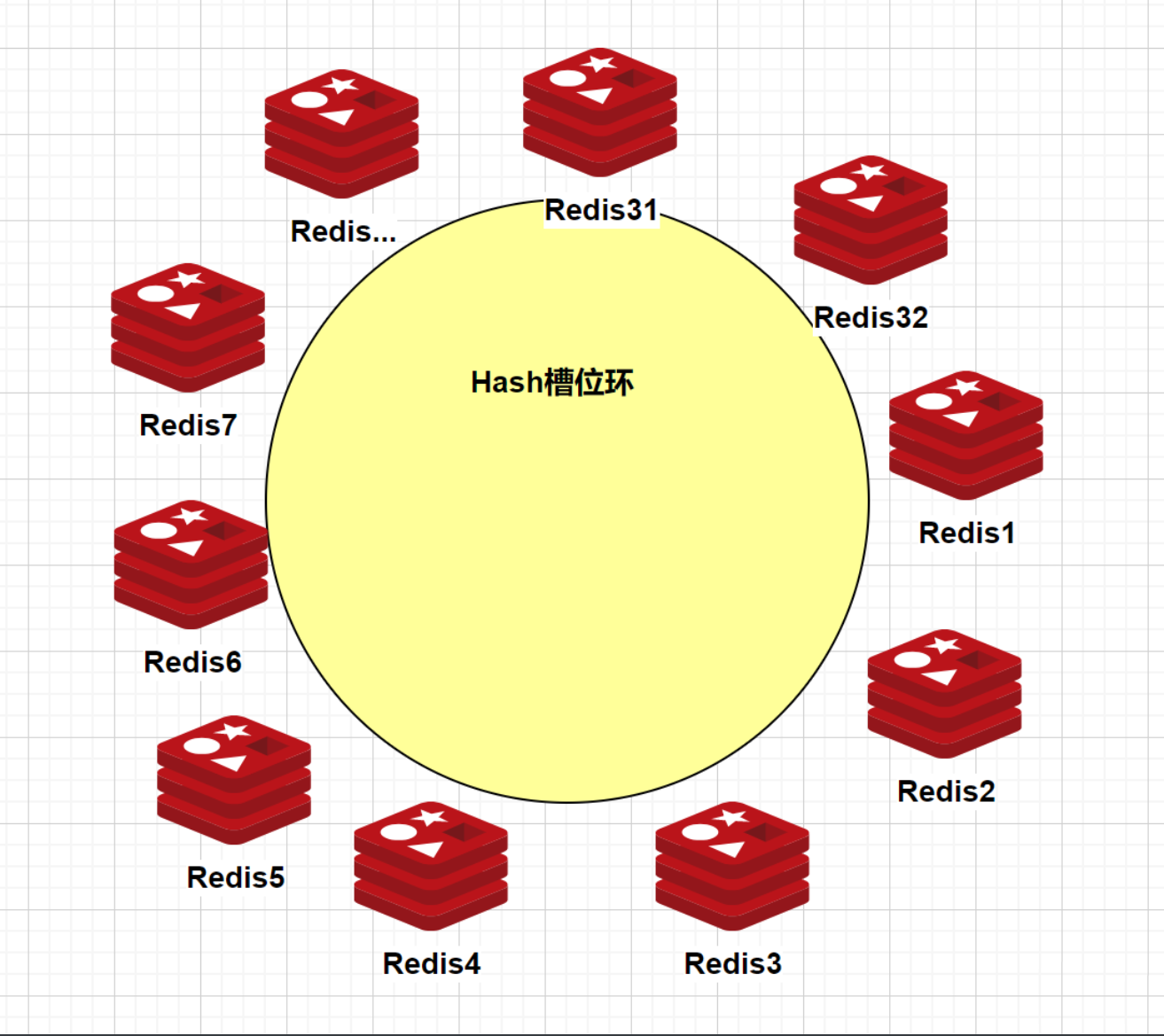
现在还是4个redis节点,那么这32个虚拟节点到4个redis物理节点做映射:
假设redis2节点被移除,那么把redis2负责的逻辑节点,二次分配到其它三个物理节点就行了,上述只是一个简单的一个虚拟节点的映射方案,无论如何,通过虚拟节点,就会大大减少了一致性哈希算法的数据倾斜问题。
三、Redis cluster数据分片(crc16 哈希算法)
看似一致性哈希算法已经够完美了,但Redis cluster的分片并没有采用。
3.1 Redis cluster分片
在Redis的Cluster集群模式中,使用了哈希槽(hash slot)的方式来进行数据分片,将整个数据集划分为16384个槽,每个节点负责部分槽。客户端访问数据时,先计算出数据对应的槽,然后直接连接到该槽所在的节点进行操作,如下图:
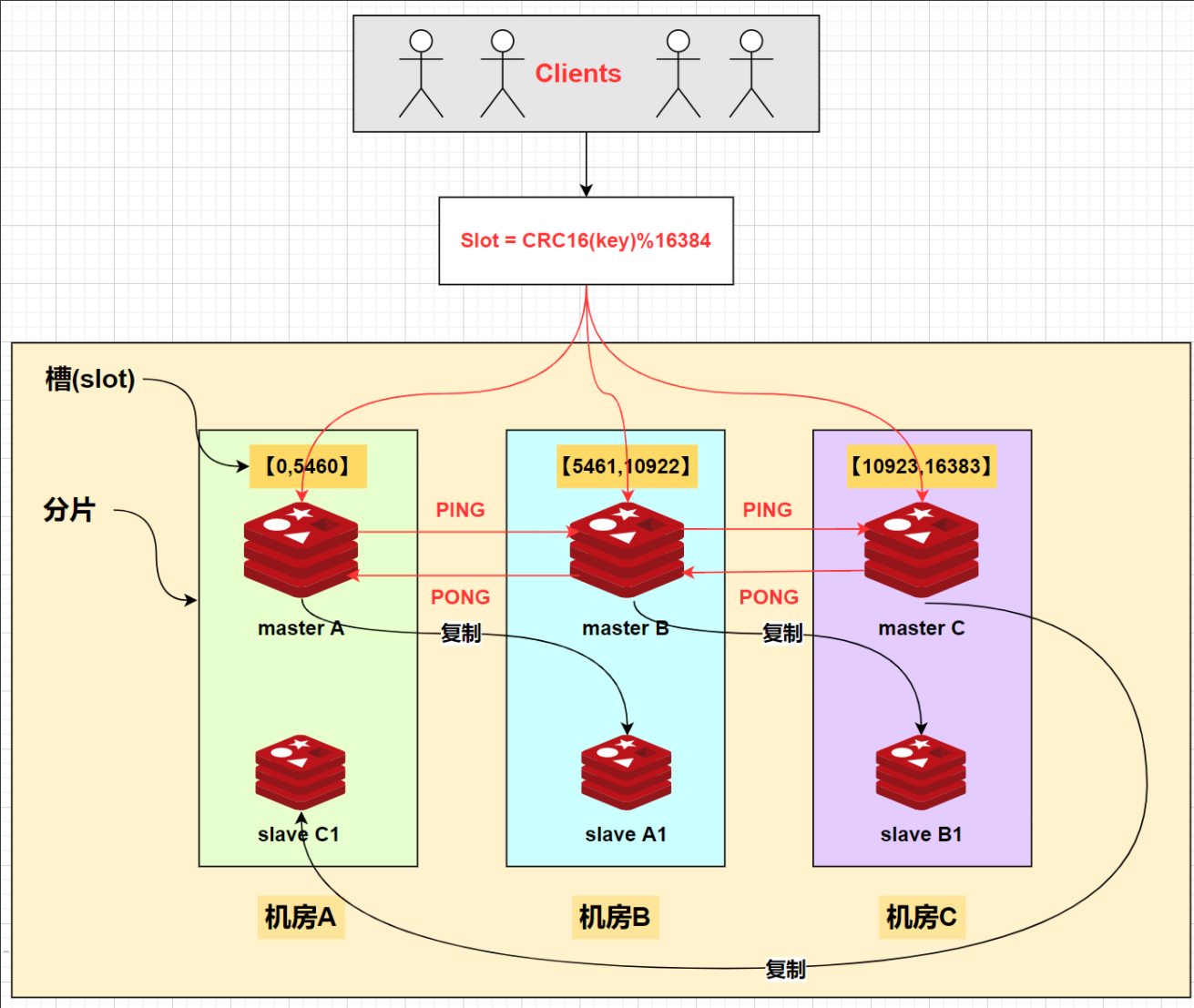
ps:上图把16384个槽均匀分配给了三个节点,当然,如果各个节点机器的性能不一样,也可以用【cluster addslots】命令为每个节点自定义分配槽的数量。
在Redis的每个节点上,都有这么两个东西:
槽(slot):它的取值范围是0~16384(2^14)。
cluster:可以理解为是一个集群管理的插件。
当我们存取key的时候,Redis会根据CRC16算法得出一个结果,然后把结果对16384取模,这样就得到了一个在0~16384范围之间的哈希槽,通过这个值,去找到对应负责该槽的节点,然后就可以进行存取操作了。
3.2 Redis节点的增加和删除
无论是增加还是删除节点,redis cluster都会让数据尽可能的均匀分布。比如,现在有三个节点:Redis1[0,5460],Redis2[5461,10922],Redis3[10924,16383]。
这时增加了一台Redis4,那么cluster就会从1、2、3的数据会迁移一部分到节点4上,实现4个节点数据均匀,这时每个节点的负责16384/4 = 4096个槽。
减少节点也同理,假设删除Redis,那么Redis4节点上数据也会均匀地迁移到1、2、3,删除后,现在每个节点负责的槽位是:16384/3=6128。
3.3 为什么是16384个槽呢?
Redis集群共有16384个槽,每个key通过CRC16校验后取模来决定放置在哪个槽位上,但是为什么 哈希槽的数量是16384(2^14)个呢,CRC16算法产生的hash是16bit,该算法可以产生2^16=65535个值。
这个问题在github上也有所讨论,Redis的作者也做过回复:
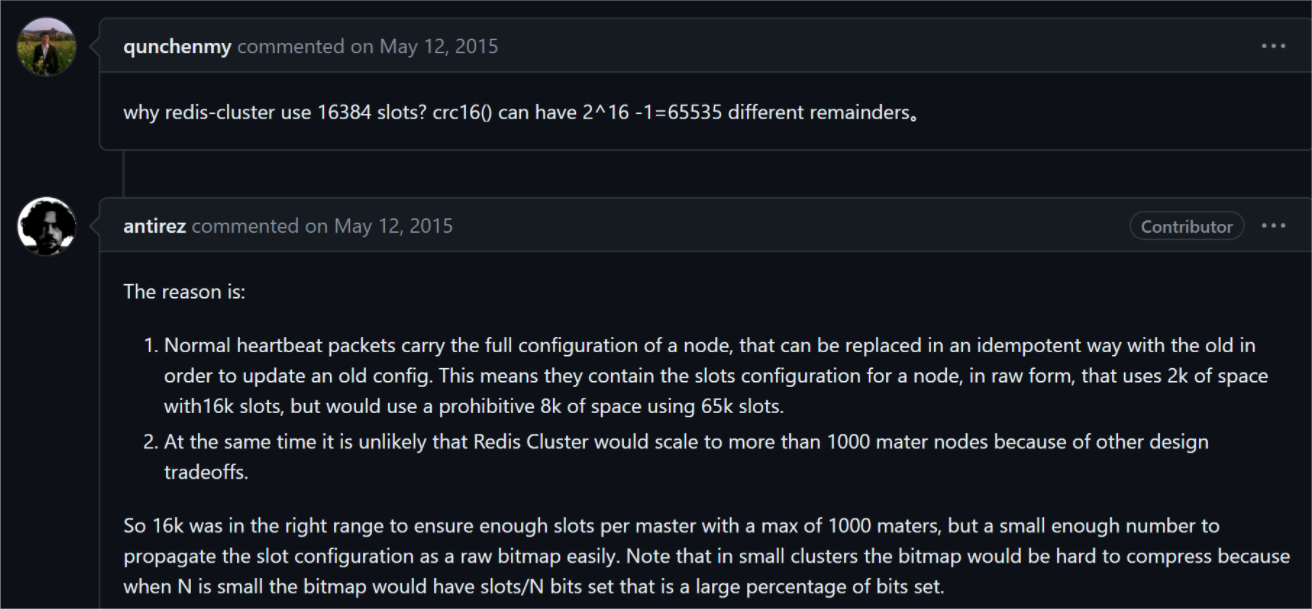
大致总结一下就是:
浪费带宽:redis节点需要发送一定数量的ping消息作为心跳包,如果槽位是65535,那么根据公式myslots【CLUSTER_SLOTS/8】,占用的空间为65535/8/1024=8kb,而16384/8/1024=2kb。
redis的集群主节点基本不可能超过1000个:集群节点越多,心跳包的消息体携带的数据越多,如果超过1000个,也会导致网络拥堵,而1000个节点以内的cluster集群,16384个槽位也足够用了。
压缩比高:redis主节点的配置信息中它所负责的哈希槽是通过bitmap的形式来保存的,在传输过程中会对bitmap压缩,但如果bitmap填充率slots/N很高的话(N为节点数),bitmap的压缩率就很低。如果节点少,而哈希槽数量多的话,bitmap的压缩率就很低。
3.4 什么是CRC16算法
CRC16(Cyclic Redundancy Check,循环冗余校验码)算法是一种广泛使用的校验算法,主要用于数据通信和数据存储等领域,例如网络通信中的错误检测和校正、数据存储中的文件校验和等。
CRC算法基于多项式除法,将输入数据按位进行多项式除法运算,最后得到一个16位的校验码。大致步骤如下:
初始化一个16位的寄存器为全1。
将输入数据的第一个字节与16位寄存器的低8位进行异或操作,结果作为新的16位寄存器的值。
将16位寄存器的高8位和低8位分别右移一位,丢弃掉最低位,即寄存器右移一位。
如果输入数据还没有处理完,转到第2步继续处理下一个字节。
如果处理完,将16位寄存器的值取反,得到CRC16校验码。
CRC16算法的优点就是计算速度快,校验效果好,缺点是只能检测错误,无法纠正错误。如果数据被修改,CRC校验值也会被修改,但无法确定是哪一位数据被修改。
四、为什么Redis用哈希槽而没用一致性哈希呢?
首先,Redis哈希槽和一致性哈希,总的流程都是差不多的,都是两个阶段:
阶段一:hash取模。
阶段二:node映射。
第一阶段都是hash之后取模分片。分为两步:
第一步:hash,hash的核心就是保证数据不倾斜,或者说保证均匀分布。redis cluster采用的是CRC16算法。
第二步:取模,就是槽位的数量,redis cluster集群有16384(2^14)个槽位,二一致性哈希是65535(2^16)。
第二阶段是node映射:
redis cluster哈希槽是静态映射(算到哪里是哪里)。
一致性哈希是哈希环顺时针映射。
通过对比,我们可以得出一个结论:
一致性哈希环顺时针映射优先考虑的是:如何实现最少的节点数据发生数据迁移,当增加或移除节点,只有离新节点最近的节点会涉及到数据迁移。
redis cluster哈希槽是静态映射,优先考虑的是如何实现数据均匀分布,当增加或移除节点时,所有的节点都会参与进来平摊压力。(我们搞集群的目的是啥?还不是单机容量不足,需要扩容多机组成集群,然后将数据尽可能的均匀分布吗)。
同时,redis cluster哈希槽静态映射还有一个优点,就是可以手动调整slots槽的分配。
redis cluster集群分为16384个槽位,一致性哈希分为65535个操作。
