.gif)


MongoDB 复制集
什么是复制集
Mongodb复制集由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,Mongodb Driver(客户端)的所有数据都写入Primary,Secondary从Primary同步写入的数据,以保持复制集内所有成员存储相同的数据集,提供数据的高可用。
复制集的作用以及好处
MongoDB 复制集的主要意义是在于实现服务高可用
它的实现依赖于两个方面的功能
数据写入时将数据迅速复制到另一个独立节点上
在接受写入的节点发生故障时自动选举出一个新的代替节点
在实现高可用得到同时,复制集实现了其他几个附加作用
数据分发:将数据从一个区域复制到另一个区域,减少另一个区域的读延迟
读写分离:不同类型的压力分别在不同的节点上执行
异地容灾:在数据中心故障时快速切换到异地
下面列举了几个使用复制的好处:
确保您数据的安全;
保障数据的高可用性;
数据恢复;
维护过程无需停机(例如备份、索引重建、压缩);
分布式读取数据;
复制集对应用程序是透明的。
Mongodb复制原理
Mongodb的复制至少需要两个节点:一个主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点的数据。
Mongodb各个节点常见的搭配方式:一主一从、一主多从
主节点记录在其上的所有操作oplog(operation log,它被存储在MongoDB的 local 数据库中,oplog 中的每个文档都代表主节点上执行的一个操作。需要重点强调的是oplog只记录改变数据库状态的操作),从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
MongoDB复制结构图如下所示:
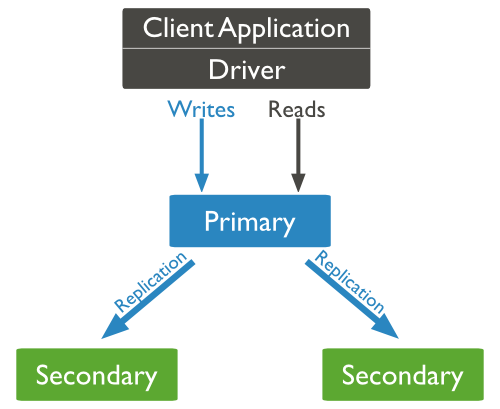
以上结构图中,客户端从主节点读取数据,在客户端写入数据到主节点时, 主节点与从节点进行数据交互保障数据的一致性
复制集概念:
MongoDB复制集(Replica Set)其实就是具有自动故障恢复功能的主从集群,与主从复制最大的区别就是在复制集中没有固定的“主节点;整个复制集会选出一个节点作为“主节点”,当其挂掉后,再在剩下的从节点中选举一个节点成为新的“主节点”,在复制集中总有一个主节点(primary)和一个或多个备份节点(secondary)。
MongoDB的复制集与我们常见的主从有所不同,主从在主机宕机后所有服务将停止,而复制集在主机宕机后,副本会接管主节点成为主节点,不会出现宕机的情况。
Primary、Secondary、Arbiter
主节点(Primary):主节点是唯一有写权限的节点,负责接收写请求,并将它们应用到数据集中,产生oplog日志。
副本节点(Secondary):副本节点是主节点的复制品,它们接收主节点的写操作,通过复制过程保持数据同步,并可提供读操作。副本节点通常用于故障切换和读操作的负载均衡。在故障时,备用节点可以根据设定的优先级别提升为首要节点,提升了复制集的可用性
仲裁节点(Arbiter):仲裁节点只参与投票,不能被选为主节点,并且不从主节点同步数据。仲裁节点本身不存储数据,是非常轻量级的服务。当复制集成员为偶数时,最好加入一个Arbiter节点,以提升复制集可用性
Oplog(操作日志)
Oplog是主节点上的特殊日志文件,记录了所有写操作,按顺序存储。副本节点通过读取Oplog并应用其中的操作来保持数据的同步。
数据同步
每个oplog都有时间戳,所有从节点都使用这个时间戳来追踪它们最后执行写操作的记录。当某个从节点准备更新自己时,会做三件事:首先,查看自己oplog里的最后一条时间戳;其次,查询主节点oplog里所有大于此时间戳的文档;最后,把那些文档应用到自己库里,并添加写操作文档到自己的oplog里。
复制状态和本地数据:
复制状态的文档记录在本地数据库local中。主节点的local数据库的内容是不会被从节点复制的。如果有不想被从节点复制的文档,可以将它放在本地数据库local中。
阻塞复制
在某些情况下,副本节点可能无法跟上主节点的写操作,导致复制延迟。这可能发生在网络问题或资源限制的情况下。副本节点会等待Oplog数据。 :::tip 为避免这种情况:
使主节点的oplog足够大
阻塞复制:在主节点使用getLastError命令加参数“w”来确保数据的同步性。w越大会导致写操作越慢。 :::
心跳机制
心跳检测有助于发现故障进行自动选举和故障转移。默认情况下复制集成员每两分钟ping一下其他成员,来弄清自己的健康状态。 如果是某一从节点出现故障只会等待从节点重新上线,而如果主节点出现故障,则复制集会开始选举,重新选出新的主节点,原主节点会降级为从节点。
选举机制
如果主节点失效,副本节点之间会触发选举过程来选出新的主节点。选举依赖于复制集配置和心跳机制。获得多数投票的节点将成为新的主节点。
MongoDB复制集中的选举机制的关键点如下:
候选节点(Candidate):在复制集中,每个成员节点都有资格成为主节点。当主节点不可用时,其他成员节点将成为候选节点,竞选成为新的主节点。
选举触发条件:选举会在以下情况下触发:
当副本节点不能与主节点保持心跳连接时,它会启动选举。
当副本节点与主节点保持连接,但主节点不再响应心跳时,选举也会触发。
选举过程:选举过程主要包括以下步骤:
候选节点开始选举并提出自己的候选者身份,请求其他节点投票支持自己。
其他节点在收到选举请求后,会验证候选节点的合法性,并投票支持其中一个候选节点。
候选节点需要获得大多数票数(超过半数)才能成为新的主节点。
如果没有候选节点获得大多数票数,选举将进入重新选举状态,直到某一节点获得足够多的票数。
选举的投票权:每个成员节点都有一个投票权数,通常为1。有时,可以配置不参与选举的成员节点,或者调整其投票权数,以影响选举结果。
优先级:每个成员节点还可以配置一个选举优先级,用于影响选举结果。拥有更高优先级的节点在选举中更有可能成为主节点。
投票复用:如果多个成员节点都认为自己有资格成为主节点,它们可能会投给不同的节点。在这种情况下,选举机制将通过选举算法来决定新的主节点。
投票回滚:选举机制还包括投票回滚,以确保新主节点在选举后具有相同的Oplog历史,以维护数据一致性。
数据回滚
在从节点成为主节点后,会认为其是复制集中的最新数据,对其他节点的操作都会回滚,即所有节点连接新的主节点重新同步。这些节点会查看自己的oplog,找出新主节点中没有执行过的操作,然后请求操作文档,替换掉自己的异常样本。
MongoDB复制集设置
1、启动一个名为rs0的Mongodb实例
mongod --port 27017 --replSet rs0在Mongo客户端使用命令rs.initiate()来启动一个新的复制集。我们可以使用rs.conf()来查看复制集的配置; 查看复制集状态使用rs.status()命令
2、多台服务器--复制集添加新成员
# 复制集添加新成员
rs.add(HOST_NAME:PORT)
# 从复制集移除成员
rs.remove(HOST_NAME:PORT)
# 向复制集添加仲裁
rs.assArb(HOST_NAME:PORT)
# 查看备份节点的复制信息
db.printSecondaryReplicationInfo() ::: tip MongoDB中你只能通过主节点将Mongo服务添加到复制集中, 判断当前运行的Mongo服务是否为主节点可以使用命令rs.isMaster() 。 :::
Docker部署MongoDB复制集设置
1、启动三个mongodb容器节点
docker run -d -p 27018:27017 --name mongo1 mongo --replSet "rs0"
docker run -d -p 27019:27017 --name mongo2 mongo --replSet "rs0"
docker run -d -p 27020:27017 --name mongo3 mongo --replSet "rs0"2、配置复制集 选取
mongo1做为master,进入容器并连接mongodb数据库
docker exec -it mongo1 mongosh
use admin
# 复制集配置,有报错的话复制出来,改成一行
config = {
"_id":"rs0",
"members":[
{"_id":0,host:"ip:27018"},
{"_id":1,host:"ip:27019"},
{"_id":2,host:"ip:27020"}
]
}
# 初始化复制集
rs.initiate(config);
# 查看复制集配置
rs.conf();
# 查看复制集状态
rs.status();复制集中参数详解
节点类型
Mongodb的节点类型:主节点(Master或者Primary)、副本节点(Slave或者Secondary)、仲裁节点、Secondary-Only节点、Hidden节点、Delayed节点、Non-Voting节点
仲裁节点:不存储数据,只负责故障转移的群体投票,这样减少了数据复制的压力;
Secondary-Only:不能成为primary节点,只能作为secondary副本节点,防止部分性能不高的节点成为主节点;
Hidden:不能被客户端指定Ip引用,也不能设置为主节点,但是可以投票,一般用于备份数据;
Delayed:可以指定一个时间延迟从primary节点同步数据,主要用于备份数据。如果实时同步,误删除数据马上同步到从节点。所以延迟复制主要用于避免用户错误。
Non-Voting:没有选举权的secondary节点,纯粹的备份数据节点。
更改节点优先级
修改节点的优先级可以触发从新选举,这样可以人工指定主节点。 使用如下命令,在主节点mongo1操作,将mongo2提升为Master:
cfg = rs.conf();
cfg.members[0].priority = 1
cfg.members[1].priority = 10
cfg.members[2].priority = 1
rs.reconfig(cfg);
# 查看集群状态:
rs.status()设置隐藏节点
隐藏节点可以在选举中投票,但是不能被客户端引用,也不能成为主节点。也就是说这个节点不能用于读写分离的场景。 使用如下命令,在主节点mongo1操作,将mongo2设置为隐藏节点: :::tip 只有优先级为0的成员才能设置为隐藏节点。如果设置优先级不为0的节点为隐藏节点,则报错。 :::
cfg = rs.conf();
cfg.members[0].priority = 1
cfg.members[1].priority = 0 # 先设置优先级为0
cfg.members[2].priority = 1
cfg.members[1].hidden = 1
rs.reconfig(cfg);
# 查看集群状态
rs.status();查看集群状态:rs.status(),该节点还是SECONDARY状态,但是通过rs.isMaster()和rs.conf()可以看到这个节点的变化:
rs.isMaster()的hosts中mongo2节点已经不可见;
rs.conf()显示该节点状态为hidden
设置仲裁节点
仲裁节点不存储数据,只是用于投票。所以仲裁节点对于服务器负载很低。
节点一旦以仲裁者的身份加入集群,他就只能是仲裁者,无法将仲裁者配置为非仲裁者,反之也是一样。
另外一个集群最多只能使用一个仲裁者,额外的仲裁者拖累选举新Master节点的速度,同时也不能提供更好的数据安全性。
初始化集群时,设置仲裁者的配置如下:
var config={
_id:"rs0",
members:[
{_id:0,host:"ip:27018"},
{_id:1,host:"ip:27019",arbiterOnly:true},
{_id:2,host:"ip:27020"}
]};使用仲裁者主要是因为MongoDB复制集需要奇数成员,而又没有足够服务器的情况。在服务器充足的情况下,不应该使用仲裁者节点。
设置Secondary-Only节点
Priority为0的节点永远不能成为主节点,所以设置Secondary-only节点只需要将其priority设置为0.
设置Non-Voting节点
cfg = rs.conf ();
# 设置不能投票
cfg.members[1].votes = 0;
rs.reconfig(cfg);复制集成员状态
复制集成员状态指的是rs.status()的stateStr字段.
STARTUP:刚加入到复制集中,配置还未加载
STARTUP2:配置已加载完,初始化状态
RECOVERING:正在恢复,不适用读
ARBITER: 仲裁者
DOWN:节点不可到达
UNKNOWN:未获取其他节点状态而不知是什么状态,一般发生在只有两个成员的架构,脑裂
REMOVED:移除复制集
ROLLBACK:数据回滚,在回滚结束时,转移到RECOVERING或SECONDARY状态
FATAL:出错。查看日志grep “replSet FATAL”找出错原因,重新做同步
PRIMARY:主节点
SECONDARY:备份节点
