.gif)


Hystrix
1、Hystrix产生背景
1.1、服务雪崩
分布式系统环境下,服务间类似依赖非常常见,一个业务调用通常依赖多个基础服务。如下图,
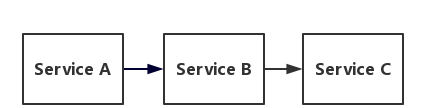
如果各个服务正常运行,那大家齐乐融融,高高兴兴的,但是如果其中一个服务崩坏掉会出现什么样的情况呢?如下图,
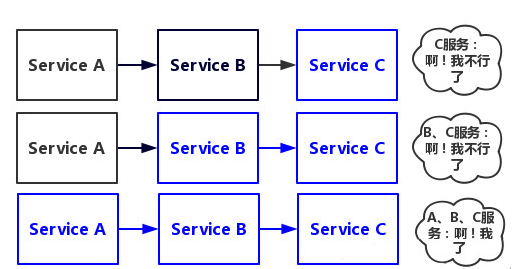
当Service A的流量波动很大,流量经常会突然性增加!那么在这种情况下,就算Service A能扛得住请求,Service B和Service C未必能扛得住这突发的请求。 此时,如果Service C因为抗不住请求,变得不可用。那么Service B的请求也会阻塞,慢慢耗尽Service B的线程资源,Service B就会变得不可用。紧接着,Service A也会不可用。
So,简单地讲。一个服务失败,导致整条链路的服务都失败的情形,我们称之为服务雪崩。
1.2、引起雪崩的原因和服务雪崩的三个阶段
原因大致有四:
1、硬件故障;
2、程序Bug;
3、缓存击穿(用户大量访问缓存中没有的键值,导致大量请求查询数据库,使数据库压力过大);
4、用户大量请求;
服务雪崩的第一阶段: 服务不可用;
第二阶段:调用端重试加大流量(用户重试/代码逻辑重试);
第三阶段:服务调用者不可用(同步等待造成的资源耗尽);
1.3、雪崩效应应对策略
针对造成雪崩效应的不同场景,可以使用不同的应对策略,没有一种通用所有场景的策略,参考如下:
硬件故障:多机房容灾、异地多活等。
流量激增:服务自动扩容、流量控制(限流、关闭重试)等。
缓存穿透:缓存预加载、缓存异步加载等。
程序BUG:修改程序bug、及时释放资源等。
同步等待:资源隔离、MQ解耦、不可用服务调用快速失败等。资源隔离通常指不同服务调用采用不同的线程池;不可用服务调用快速失败一般通过熔断器模式结合超时机制实现。
综上所述,如果一个应用不能对来自依赖的故障进行隔离,那该应用本身就处在被拖垮的风险中。 因此,为了构建稳定、可靠的分布式系统,我们的服务应当具有自我保护能力,当依赖服务不可用时,当前服务启动自我保护功能,从而避免发生雪崩效应。本文将重点介绍使用Hystrix解决同步等待的雪崩问题。
2、Hystrix
2.1、以项目案例开始,快速入门(使用IDEA)
场景假设1( 服务提供方报错) : 在服务提供端中因为访问不到数据库中的数据(比如数据不存在,或是数据库压力过大,查询请求队列中),在这种情况下,服务提供方这边如何实现服务降级,以防止服务雪崩.
1、使用IDEA新建一个 microservice-provider-hystrix 工程
2、因为此工程要受到Hystrix保护,所以加入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>3、在microservice-provider-hystrix 工程的启动类上启用断路器 在启动类上加入注解 @EnableCircuitBreaker //启用断路器 注意: 这里其实也可以使用 spring cloud应用中的@SpringCloudApplication注解,因为它已经自带了这些注解,源码如下:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootApplication
@EnableDiscoveryClient
@EnableCircuitBreaker
public @interface SpringCloudApplication {
}4、在 ProductController中加入断路逻辑
@RequestMapping("/get/{id}")
@HystrixCommand(fallbackMethod="errorCallBack") //模仿没有这个数据时,服务降级
public Object get(@PathVariable("id") long id){
Product p=this.productService.findById(id);
if( p==null){
throw new RuntimeException("查无此产品");
}
return p;
}
//指定一个降级的方法
public Object errorCallBack( @PathVariable("id") long id ){
return id+"不存在,error";
}5、启动provider服务后测试
输出:100不存在,error小结: 服务降级 由服务提供方 处理
场景假设2: 因为网络抖动,或服务端维护导致的服务暂时不可用,此时是客户端联接不到服务器,因为feign有重试机制,这样会导致系统长时间不响应,那么在这种情况上如何通过 feign+hystrix 在服务的消费方实现服务熔断(回退机制)呢?
首先确认一下我们使用的客户端是 microservice-consumer-feign , feign中自带了 hystrix,但并没有启动,所以要配置启用hystrix,修改 application.yml
feign:
hystrix:
enabled: true我们的服务消费方的feign操作接口位于 microservice-interface中,所以要在这里配置
1、建立一个包 fallback,用于存回退处理类 IProductClientServiceFallbackFactory,这个类有出现请求异常时的处理
package com.yc.springcloud2.fallback;
import com.yc.springcloud2.bean.Product;
import com.yc.springcloud2.service.IProductClientService;
import feign.hystrix.FallbackFactory;
import java.util.List;
@Component //必须被spring 托管
public class IProductClientServiceFallbackFactory implements FallbackFactory<IProductClientService> {
@Override
public IProductClientService create(Throwable throwable) {
//这里提供请求方法出问题时回退处理机制
return new IProductClientService(){
@Override
public Product getProduct(long id) {
Product p=new Product();
p.setProductId(999999999L);
p.setProductDesc("error");
return p;
}
@Override
public List<Product> listProduct() {
return null;
}
@Override
public boolean addPorduct(Product product) {
return false;
}
};
}
}2、在业务接口上加入 fallbackFactory属性指定异常处理类
@FeignClient(name="MICROSERVICE-PROVIDER-PRODUCT",
configuration = FeignClientConfig.class,
fallbackFactory = IProductClientServiceFallbackFactory.class) // 配置要按自定义的类FeignClientConfig
public interface IProductClientService {3、启动 microservice-consumer-feign客户端进行测试, 在测试时,尝试关闭生产端,看它是否回退
{
productId:999999999,
productName:null,
productDesc:"error"
}小结: 服务熔断在消费端 处理
2.1、Hystrix设计目标
对来自依赖的延迟和故障进行防护和控制——这些依赖通常都是通过网络访问的 阻止故障的连锁反应 快速失败并迅速恢复 回退并优雅降级 提供近实时的监控与告警
2.3、Hystrix遵循的设计原则
防止任何单独的依赖耗尽资源(线程) 过载立即切断并快速失败,防止排队 尽可能提供回退以保护用户免受故障 使用隔离技术(例如隔板,泳道和断路器模式)来限制任何一个依赖的影响 通过近实时的指标,监控和告警,确保故障被及时发现 通过动态修改配置属性,确保故障及时恢复 防止整个依赖客户端执行失败,而不仅仅是网络通信
2.4、Hystrix如何实现这些设计目标?
使用命令模式将所有对外部服务(或依赖关系)的调用包装在HystrixCommand或HystrixObservableCommand对象中,并将该对象放在单独的线程中执行; 每个依赖都维护着一个线程池(或信号量),线程池被耗尽则拒绝请求(而不是让请求排队)。 记录请求成功,失败,超时和线程拒绝。 服务错误百分比超过了阈值,熔断器开关自动打开,一段时间内停止对该服务的所有请求。 请求失败,被拒绝,超时或熔断时执行降级逻辑。 近实时地监控指标和配置的修改。
2.5、Hystrix简单示例
开始深入Hystrix原理之前,我们先简单看一个示例。
第一步,继承HystrixCommand实现自己的command,在command的构造方法中需要配置请求被执行需要的参数,并组合实际发送请求的对象,代码如下:
public class QueryOrderIdCommand extends HystrixCommand<Integer> {
private final static Logger logger = LoggerFactory.getLogger(QueryOrderIdCommand.class);
private OrderServiceProvider orderServiceProvider;
public QueryOrderIdCommand(OrderServiceProvider orderServiceProvider) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("orderService"))
.andCommandKey(HystrixCommandKey.Factory.asKey("queryByOrderId"))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withCircuitBreakerRequestVolumeThreshold(10)//至少有10个请求,熔断器才进行错误率的计算
.withCircuitBreakerSleepWindowInMilliseconds(5000)//熔断器中断请求5秒后会进入半打开状态,放部分流量过去重试
.withCircuitBreakerErrorThresholdPercentage(50)//错误率达到50开启熔断保护
.withExecutionTimeoutEnabled(true))
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties
.Setter().withCoreSize(10)));
this.orderServiceProvider = orderServiceProvider;
}
@Override
protected Integer run() {
return orderServiceProvider.queryByOrderId();
}
@Override
protected Integer getFallback() {
return -1;
}
}第二步,调用HystrixCommand的执行方法发起实际请求。
@Test
public void testQueryByOrderIdCommand() {
Integer r = new QueryOrderIdCommand(orderServiceProvider).execute();
logger.info("result:{}", r);
}2.6、Hystrix处理流程
Hystrix整个工作流如下:
1、构造一个 HystrixCommand或HystrixObservableCommand对象,用于封装请求,并在构造方法配置请求被执行需要的参数;
2、执行命令,Hystrix提供了4种执行命令的方法,后面详述;
3、判断是否使用缓存响应请求,若启用了缓存,且缓存可用,直接使用缓存响应请求。Hystrix支持请求缓存,但需要用户自定义启动;
4、判断熔断器是否打开,如果打开,跳到第8步;
5、判断线程池/队列/信号量是否已满,已满则跳到第8步;
6、执行HystrixObservableCommand.construct()或HystrixCommand.run(),如果执行失败或者超时,跳到第8步;否则,跳到第9步;
7、统计熔断器监控指标;
8、走Fallback备用逻辑
9、返回请求响应 *
2.7、执行命令的几种方法
Hystrix提供了4种执行命令的方法,execute()和queue() 适用于HystrixCommand对象,而observe()和toObservable()适用于HystrixObservableCommand对象。
execute()
以同步堵塞方式执行run(),只支持接收一个值对象。hystrix会从线程池中取一个线程来执行run(),并等待返回值。
queue()
以异步非阻塞方式执行run(),只支持接收一个值对象。调用queue()就直接返回一个Future对象。可通过 Future.get()拿到run()的返回结果,但Future.get()是阻塞执行的。若执行成功,Future.get()返回单个返回值。当执行失败时,如果没有重写fallback,Future.get()抛出异常。
observe()
事件注册前执行run()/construct(),支持接收多个值对象,取决于发射源。调用observe()会返回一个hot Observable,也就是说,调用observe()自动触发执行run()/construct(),无论是否存在订阅者。
如果继承的是HystrixCommand,hystrix会从线程池中取一个线程以非阻塞方式执行run();如果继承的是HystrixObservableCommand,将以调用线程阻塞执行construct()。
observe()使用方法:
调用observe()会返回一个Observable对象 调用这个Observable对象的subscribe()方法完成事件注册,从而获取结果
toObservable()
事件注册后执行run()/construct(),支持接收多个值对象,取决于发射源。调用toObservable()会返回一个cold Observable,也就是说,调用toObservable()不会立即触发执行run()/construct(),必须有订阅者订阅Observable时才会执行。
如果继承的是HystrixCommand,hystrix会从线程池中取一个线程以非阻塞方式执行run(),调用线程不必等待run();如果继承的是HystrixObservableCommand,将以调用线程堵塞执行construct(),调用线程需等待construct()执行完才能继续往下走。
toObservable()使用方法:
调用observe()会返回一个Observable对象 调用这个Observable对象的subscribe()方法完成事件注册,从而获取结果 需注意的是,HystrixCommand也支持toObservable()和observe(),但是即使将HystrixCommand转换成Observable,它也只能发射一个值对象。只有HystrixObservableCommand才支持发射多个值对象。
几种方法的关系
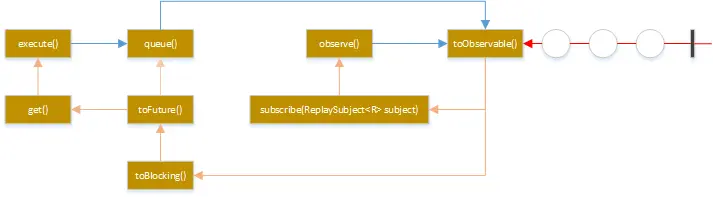
execute()实际是调用了queue().get()
queue()实际调用了toObservable().toBlocking().toFuture()
observe()实际调用toObservable()获得一个cold Observable,再创建一个ReplaySubject对象订阅Observable,将源Observable转化为hot Observable。因此调用observe()会自动触发执行run()/construct()。
Hystrix总是以Observable的形式作为响应返回,不同执行命令的方法只是进行了相应的转换。
