.gif)


ElasticsearchTemplate 集成
AI-摘要
WenXi GPT
AI初始化中...
介绍自己
生成本文简介
推荐相关文章
前往主页
前往tianli博客
ElasticSearch集成Spring之ElasticsearchTemplate
1. 简介
<!-- elasticsearch的spring-data包 -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>x.y.z.RELEASE</version>
</dependency>
<!-- elasticsearch客户端,version填入本地安装好的ES版本号 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>x.y.z</version>
</dependency>
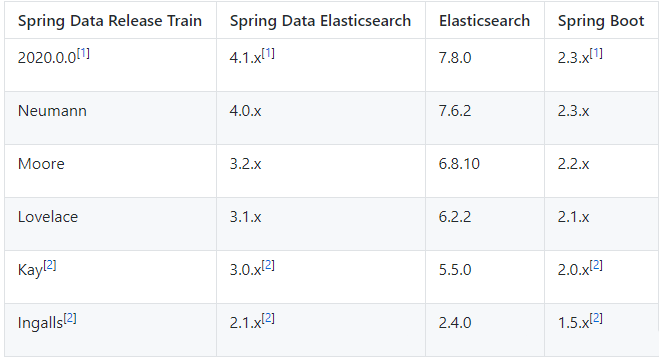
spring-data-elasticsearch与elasticsearch的版本对应关系:
2. 配置文件
1、配置application.yml
spring:
elasticsearch:
rest:
uris: http://192.168.220.11:9200 ---ES的连接地址,多个地址用逗号分隔
username: ---用户名
password: ---密码
connection-timeout: 1000 ---连接超时时间
read-timeout: 1000 ---读取超时时间
2、创建映射对象
我这里定义了一个类,并使用@Document定义员工类关联的index索引、typeso因类型,shards主分区,replicas副分区。
在@Document中有个属性是createIndex,表示当索引不存在时,操作这个对象会默认创建索引,默认为true。如果你的索引设置比较多,就把createIndex设置为false,再通过其他接口手动触发创建索引操作。
- @Id 表示索引的主键
- @Field 用来描述字段的ES数据类型,是否分词等配置,等于Mapping描述
/**
* 员工对象
* <p>
* 注解:@Document用来声明Java对象与ElasticSearch索引的关系
* indexName 索引名称
* type 索引类型
* shards 主分区数量,默认5
* replicas 副本分区数量,默认1
* createIndex 索引不存在时,是否自动创建索引,默认true*/
@Getter
@Setter
@NoArgsConstructor
@Accessors(chain = true)
@Document(indexName = "employee_index", type = "employee_type", shards = 1, replicas = 0,createIndex = true)
public class EmployeeBean {
@Id
private String id;
/**
* 员工编码
*/
@Field(type = FieldType.Keyword)
private String studentCode;
/**
* 员工姓名
*/
@Field(type = FieldType.Keyword)
private String name;
/**
* 员工简历
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String desc;
/**
* 员工住址
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private Integer type;
/**
* 手机号码
*/
@Field(type = FieldType.Keyword)
private String mobile;
}
3、创建Repository接口
Repository需要继承ElasticsearchRepository接口,参数<映射对象,主键ID的数据类型>。之后Repository类就可以使用类似JPA的方法操作ElasticSearch数据。
@Component
public interface EmployeeRepository extends ElasticsearchRepository<EmployeeBean, String> {
}
我们在操作索引和数据时,需要引用这2个类
@Autowired
private ElasticsearchRestTemplate restTemplate;
@Autowired
private EmployeeRepository repository;
3. 索引操作
1、判断索引是否存在
/**
* 判断索引是否存在
* @return boolean
*/
public boolean indexExists() {
return elasticsearchTemplate.indexExists(EmployeeBean.class);
}
/**
* 判断索引是否存在
* @param indexName 索引名称
* @return boolean
*/
public boolean indexExists(String indexName) {
return elasticsearchTemplate.indexExists(indexName);
}
2、创建索引
/**
* 创建索引(推荐使用:因为Java对象已经通过注解描述了Setting和Mapping)
* @return boolean
*/
public boolean indexCreate() {
return elasticsearchTemplate.createIndex(EmployeeBean .class);
}
/**
* 创建索引
* @param indexName 索引名称
* @return boolean
*/
public boolean indexCreate(String indexName) {
return elasticsearchTemplate.createIndex(indexName);
}
3、删除索引
/**
* 索引删除
* @param indexName 索引名称
* @return boolean
*/
public boolean indexDelete(String indexName) {
return elasticsearchTemplate.deleteIndex(indexName);
}
数据操作
1、新增数据
/**
* 新增数据
* @param bean 数据对象
*/
public void save(EmployeeBean bean) {
repository.save(bean);
}
/**
* 批量新增数据
* @param list 数据集合
*/
public void saveAll(List<EmployeeBean> list) {
repository.saveAll(list);
}
2、修改数据
/**
* 修改数据
* @param indexName 索引名称
* @param type 索引类型
* @param bean 修改数据对象,ID不能为空
*/
public void update(String indexName, String type, EmployeeBean bean) {
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.retryOnConflict(1);//冲突重试
updateRequest.doc(JSONUtil.toJsonStr(bean), XContentType.JSON);
updateRequest.routing(bean.getId());//默认是_id来路由的,用来路由到不同的shard,会对这个值做hash,然后映射到shard。所以分片
UpdateQuery query = new UpdateQueryBuilder().withIndexName(indexName).withType(type).withId(bean.getId())
.withDoUpsert(true)//不加默认false。true表示更新时不存在就插入
.withClass(EmployeeBean.class).withUpdateRequest(updateRequest).build();
UpdateResponse updateResponse = restTemplate.update(query);
}
3、删除数据
/**
* 根据ID,删除数据
* @param id 数据ID
*/public void deleteById(String id) {
repository.deleteById(id);
}
/**
* 根据对象删除数据,主键ID不能为空
* @param bean 对象
*/public void deleteByBean(EmployeeBean bean) {
repository.delete(bean);
}
/**
* 根据对象集合,批量删除
* @param beanList 对象集合
*/public void deleteAll(List<EmployeeBean> beanList) {
repository.deleteAll(beanList);
}
/**
* 删除所有
*/public void deleteAll() {
repository.deleteAll();
}
/**
* 根据条件,自定义删除(在setQuery中的条件,可以根据需求自由拼接各种参数,与查询方法一样)
* @param indexName 索引
* @param type 索引类型
*/public void delete(String indexName, String type) {
DeleteQuery deleteQuery = new DeleteQuery();
deleteQuery.setIndex(indexName);
deleteQuery.setType(type);//建index没配置就是类名全小写
deleteQuery.setQuery(new BoolQueryBuilder().must(QueryBuilders.termQuery("mobile","13526568454")));
restTemplate.delete(deleteQuery);
}
4、批量操作
/**
* 批量新增
* @param indexName 索引名称
* @param type 索引类型
* @param beanList 新增对象集合
*/public void batchSave(String indexName, String type, List<EmployeeBean> beanList) {
List<IndexQuery> queries = new ArrayList<>();
IndexQuery indexQuery;
int counter = 0;
for (EmployeeBean item : beanList) {
indexQuery = new IndexQuery();
indexQuery.setId(item.getId());
indexQuery.setSource(JSONUtil.toJsonStr(item));
indexQuery.setIndexName(indexName);
indexQuery.setType(type);
queries.add(indexQuery);
//分批提交索引
if (counter != 0 && counter % 1000 == 0) {
restTemplate.bulkIndex(queries);
queries.clear();
System.out.println("bulkIndex counter : " + counter);
}
counter++;
}
//不足批的索引最后不要忘记提交
if (queries.size() > 0) {
restTemplate.bulkIndex(queries);
}
restTemplate.refresh(indexName);
}
/**
* 批量修改
* @param indexName 索引名称
* @param type 索引类型
* @param beanList 修改对象集合
*/public void batchUpdate(String indexName, String type, List<EmployeeBean> beanList) {
List<UpdateQuery> queries = new ArrayList<>();
UpdateQuery updateQuery;
UpdateRequest updateRequest;
int counter = 0;
for (EmployeeBean item : beanList) {
updateRequest = new UpdateRequest();
updateRequest.retryOnConflict(1);//冲突重试
updateRequest.doc(item);
updateRequest.routing(item.getId());
updateQuery = new UpdateQuery();
updateQuery.setId(item.getId());
updateQuery.setDoUpsert(true);
updateQuery.setUpdateRequest(updateRequest);
updateQuery.setIndexName(indexName);
updateQuery.setType(type);
queries.add(updateQuery);
//分批提交索引
if (counter != 0 && counter % 1000 == 0) {
restTemplate.bulkUpdate(queries);
queries.clear();
System.out.println("bulkIndex counter : " + counter);
}
counter++;
}
//不足批的索引最后不要忘记提交
if (queries.size() > 0) {
restTemplate.bulkUpdate(queries);
}
restTemplate.refresh(indexName);
}
5、数据查询
/**
* 数据查询,返回List
* @param field 查询字段
* @param value 查询值
* @return List<EmployeeBean>
*/
@Override
public List<EmployeeBean> queryMatchList(String field, String value) {
MatchQueryBuilder builder = QueryBuilders.matchQuery(field, value);
SearchQuery searchQuery = new NativeSearchQuery(builder);
return restTemplate.queryForList(searchQuery, EmployeeBean.class);
}
/**
* 数据查询,返回Page
* @param field 查询字段
* @param value 查询值
* @return AggregatedPage<EmployeeBean>
*/
@Override
public AggregatedPage<EmployeeBean> queryMatchPage(String field, String value) {
MatchQueryBuilder builder = QueryBuilders.matchQuery(field, value);
SearchQuery searchQuery = new NativeSearchQuery(builder).setPageable(PageRequest.of(0, 100));
AggregatedPage<EmployeeBean> page = restTemplate.queryForPage(searchQuery, EmployeeBean.class);
long totalElements = page.getTotalElements(); // 总记录数
int totalPages = page.getTotalPages(); // 总页数
int pageNumber = page.getPageable().getPageNumber(); // 当前页号
List<EmployeeBean> beanList = page.toList(); // 当前页数据集
Set<EmployeeBean> beanSet = page.toSet(); // 当前页数据集
return page;
}
QueryBuilders对象是用于创建查询方法的,支持多种查询类型,常用的查询API包括以下方法:
/**
* 关键字匹配查询
*
* @param name 字段的名称
* @param value 查询值
*/
public static TermQueryBuilder termQuery(String name, String value) {
return new TermQueryBuilder(name, value);
}
public static TermQueryBuilder termQuery(String name, int value) {
return new TermQueryBuilder(name, value);
}
public static TermQueryBuilder termQuery(String name, long value) {
return new TermQueryBuilder(name, value);
}
public static TermQueryBuilder termQuery(String name, float value) {
return new TermQueryBuilder(name, value);
}
public static TermQueryBuilder termQuery(String name, double value) {
return new TermQueryBuilder(name, value);
}
public static TermQueryBuilder termQuery(String name, boolean value) {
return new TermQueryBuilder(name, value);
}
public static TermQueryBuilder termQuery(String name, Object value) {
return new TermQueryBuilder(name, value);
}
/**
* 关键字查询,同时匹配多个关键字
*
* @param name 字段名称
* @param values 查询值
*/
public static TermsQueryBuilder termsQuery(String name, String... values) {
return new TermsQueryBuilder(name, values);
}
/**
* 创建一个匹配多个关键字的查询,返回boolean
*
* @param fieldNames 字段名称
* @param text 查询值
*/
public static MultiMatchQueryBuilder multiMatchQuery(Object text, String... fieldNames) {
return new MultiMatchQueryBuilder(text, fieldNames); // BOOLEAN is the default
}
/**
* 关键字,精确匹配
*
* @param name 字段名称
* @param text 查询值
*/
public static MatchQueryBuilder matchQuery(String name, Object text) {
return new MatchQueryBuilder(name, text);
}
/**
* 关键字范围查询(后面跟范围条件)
*
* @param name 字段名称
*/
public static RangeQueryBuilder rangeQuery(String name) {
return new RangeQueryBuilder(name);
}
/**
* 判断字段是否有值
*
* @param name 字段名称
*/
public static ExistsQueryBuilder existsQuery(String name) {
return new ExistsQueryBuilder(name);
}
/**
* 模糊查询
*
* @param name 字段名称
* @param value 查询值
*/
public static FuzzyQueryBuilder fuzzyQuery(String name, String value) {
return new FuzzyQueryBuilder(name, value);
}
/**
* 组合查询对象,可以同时引用上面的所有查询对象
*/
public static BoolQueryBuilder boolQuery() {
return new BoolQueryBuilder();
}
6、聚合查询
AggregationBuilders对象是用于创建聚合方法的,支持多种查询类型,常用的查询API包括以下方法:
/**
* 根据字段聚合,统计该字段的每个值的数量
*/
public static TermsAggregationBuilder terms(String name) {
return new TermsAggregationBuilder(name, null);
}
/**
* 统计操作的,过滤条件
*/
public static FilterAggregationBuilder filter(String name, QueryBuilder filter) {
return new FilterAggregationBuilder(name, filter);
}
/**
* 设置多个过滤条件
*/
public static FiltersAggregationBuilder filters(String name, KeyedFilter... filters) {
return new FiltersAggregationBuilder(name, filters);
}
/**
* 统计该字段的数据总数
*/
public static ValueCountAggregationBuilder count(String name) {
return new ValueCountAggregationBuilder(name, null);
}
/**
* 计算平均值
*/
public static AvgAggregationBuilder avg(String name) {
return new AvgAggregationBuilder(name);
}
/**
* 计算最大值
*/
public static MaxAggregationBuilder max(String name) {
return new MaxAggregationBuilder(name);
}
/**
* 计算最小值
*/
public static MinAggregationBuilder min(String name) {
return new MinAggregationBuilder(name);
}
/**
* 计算总数
*/
public static SumAggregationBuilder sum(String name) {
return new SumAggregationBuilder(name);
}
示例
排序
Pageable pageable= new PageRequest(0, 20,new Sort(Sort.Direction.DESC, "name"));
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.queryStringQuery("菜鸟"))
.withPageable(pageable)
.build();
Page<BookEntity> list = elasticsearchTemplate.queryForPage(searchQuery, BookEntity.class);
模糊查询
Pageable pageable = new PageRequest(0, 10);
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("name", "菜鸟"))
.withPageable(pageable)
.build();
List<BookEntity> list = elasticsearchTemplate.queryForList(searchQuery, BookEntity.class);
其余匹配
Pageable pageable = new PageRequest(0, 10);
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchPhraseQuery("name", "菜鸟"))
.withPageable(pageable)
.build();
List<BookEntity> list = elasticsearchTemplate.queryForList(searchQuery, BookEntity.class);
Term全等查询
Pageable pageable = new PageRequest(0, 10);
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.termQuery("name", "菜鸟"))
.withPageable(pageable)
.build();
List<BookEntity> list = elasticsearchTemplate.queryForList(searchQuery, BookEntity.class);
GetQuery根据id查询
GetQuery getQuery = GetQuery.getById(String.valueOf(admin.getId()));
Admin admin = template.queryForObject(getQuery, Admin.class);
RangeQuery范围查询
- 对于字符串字段,TermRangeQuery,对于数字/日期字段,查询是NumericRangeQuery
范围查询接受以下参数: - gte: 大于或等于
- gt: 大于
- lte: 小于或等于
- lt: 小于
- boost: 设置查询的提升值,默认为1.0
- format(String format) 对于日期字段,我们可以设置要使用的格式,而不是映射器格式
- timeZone 时区
- from 范围查询的from部分
RangeQueryBuilder createTime = QueryBuilders.rangeQuery("createTime").from(questions.getStartTime()).to(questions.getEndTime());
boolQueryBuilder.should(createTime);
组合查询
即boolQuery,可以设置多个条件的查询方式。它的作用是用来组合多个Query,有四种方式来组合,must,mustnot,filter,should。
- must代表返回的文档必须满足must子句的条件,会参与计算分值;
- filter代表返回的文档必须满足filter子句的条件,但不会参与计算分值;
- should代表返回的文档可能满足should子句的条件,也可能不满足,有多个should时满足任何一个就可以,通过minimum_should_match设置至少满足几个。
- mustnot代表必须不满足子句的条件。
QueryBuilder filterQuery = QueryBuilders
.boolQuery()
.filter(QueryBuilders.termQuery("name", "菜鸟"))
.filter(QueryBuilders.termQuery("author", "小菜"));
List<BookEntity> list = elasticsearchTemplate.queryForList(filterQuery, BookEntity.class);
组合查询举例:should
NativeSearchQueryBuilder query = new NativeSearchQueryBuilder();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("id", "b31ea3a48f0f48738ecbc4a25534d6c6");
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", "你好");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.should(matchQueryBuilder); // or
boolQueryBuilder.should(termQueryBuilder);
query.withQuery(boolQueryBuilder);

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果